Reflection and Next Steps
Measure what you learned, identify your next frontier, and plan how to keep building.
What you'll learn
The Pre/Post Self-Assessment
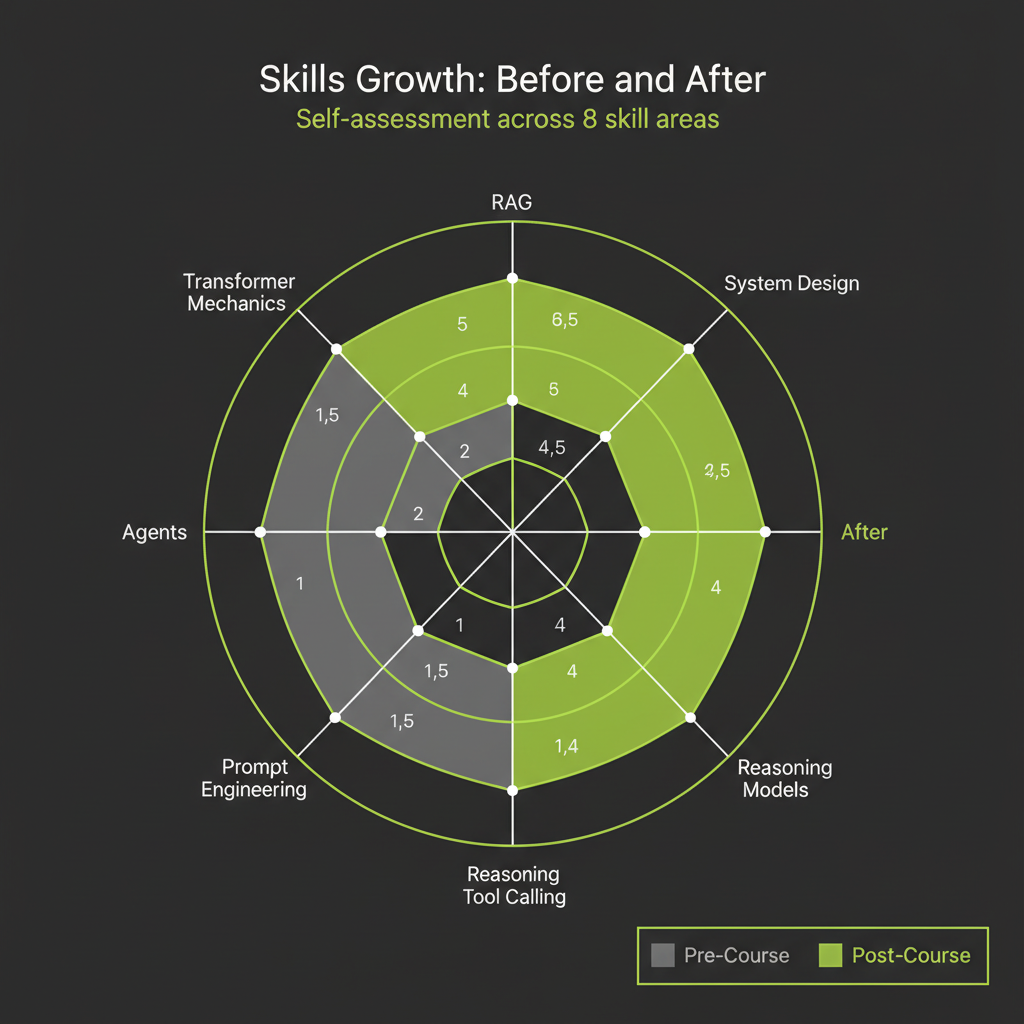
You have reached the final module. Before looking forward, look back. In Module 1, you arrived with some level of AI awareness and TypeScript proficiency. Now, 16 modules later, you have built six applications, worked with transformers, RAG, agents, reasoning models, and multimodal systems. The question is: how much did you actually grow?
Be honest. Identifying real gaps now is more valuable than inflating confidence scores. The self-assessment is for you, not for a grade. Accurate self-knowledge is what separates engineers who plateau from engineers who keep growing.
Revisit the skill inventory — rate yourself again
Rate yourself on each of the following skill areas using a 1–5 scale (1 = no practical ability, 3 = can do with reference material, 5 = can do confidently from memory). If you did this assessment at the start of the course, compare your before and after ratings:
Skill Area Before After Change
-------------------------------------------------------
Transformer mechanics __ __ __
RAG systems __ __ __
Prompt engineering __ __ __
Agents and tool calling __ __ __
Reasoning / extended thinking __ __ __
Multimodal (vision + generation) __ __ __
System design (AI applications) __ __ __
Deployment and production __ __ __Where did you grow most? Where do gaps remain?
Look at your ratings. The areas with the largest positive change are where the course had the most impact. The areas that remain at 3 or below are your next learning targets. Most learners find that the hands-on build projects (RAG chatbot, agent, deep research, multimodal) produce the largest skill jumps, while conceptual topics (transformer mechanics, training pipeline) show more modest gains unless actively reinforced through practice.
What You Built
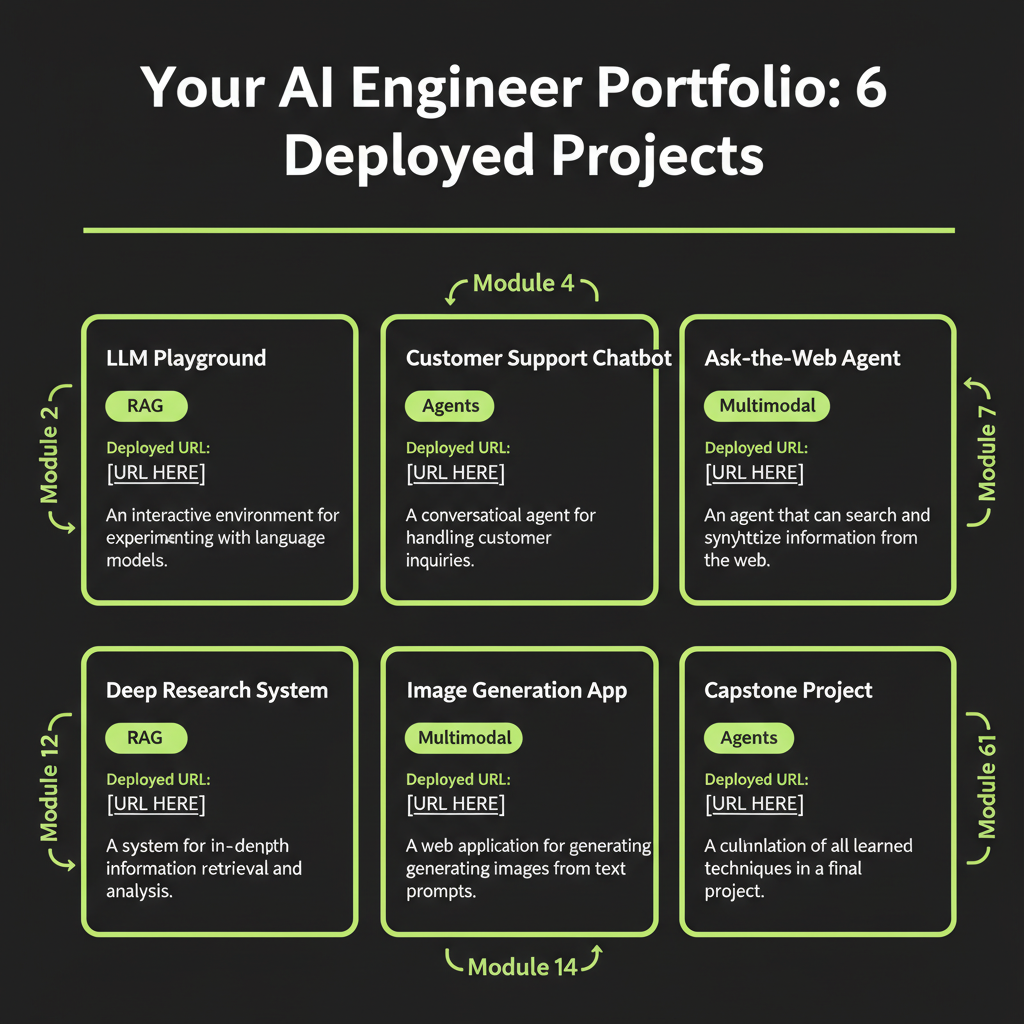
Inventory of builds
Over the course of 17 modules, you built six deployed applications. Each demonstrates a different core AI engineering capability:
The portfolio value
Six deployed URLs that demonstrate full-stack AI engineering capability. When you share these with a client or employer, the conversation shifts from "can you do AI work?" to "which of these projects is most relevant to our needs?" That is the difference between claiming a skill and demonstrating it.
Kirkpatrick Evaluation (as Reflection Tool)
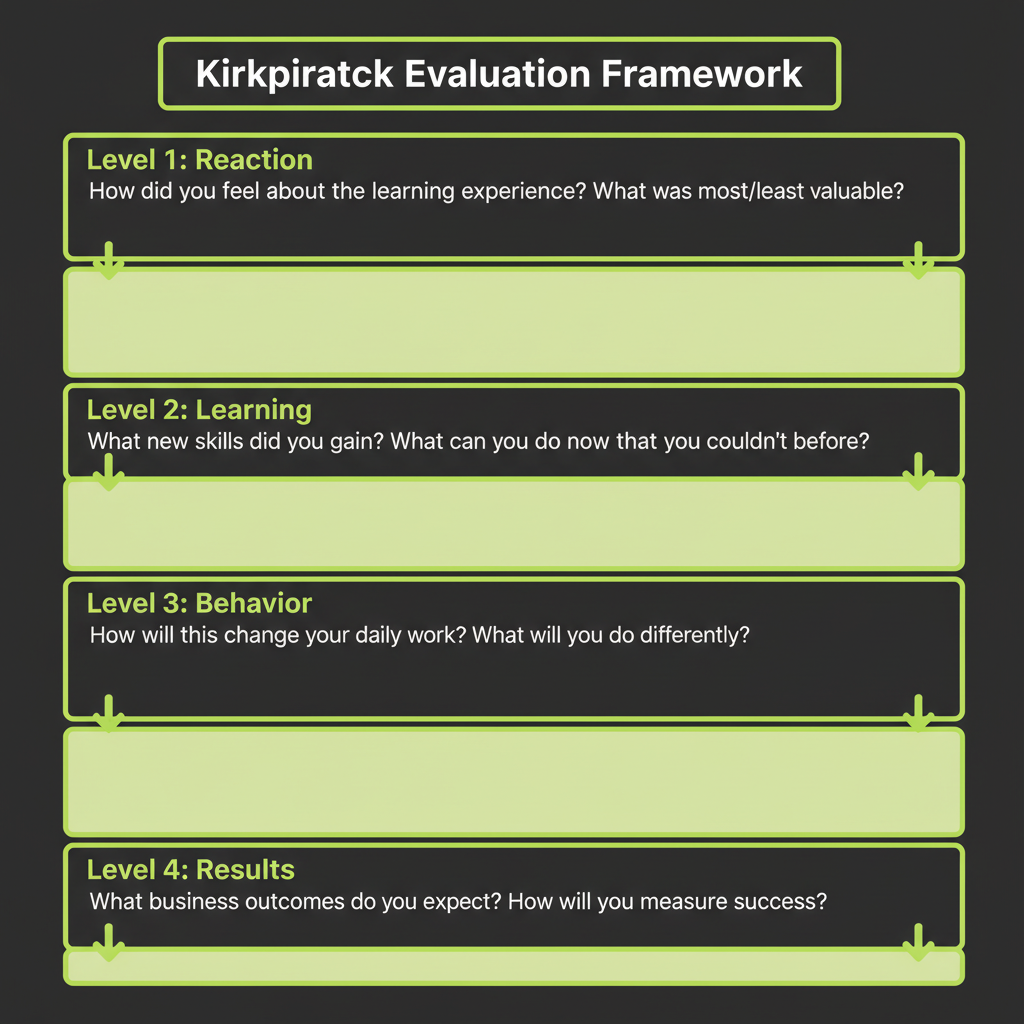
The Kirkpatrick model is the standard framework for evaluating training effectiveness. Here, you will use it as a reflective tool rather than a formal evaluation. Work through each level honestly.
Level 1 — Reaction: What was your experience?
Rate each part of the course on engagement and usefulness:
- Which module was most engaging? Why?
- Which module was hardest? Was the difficulty productive (you learned from it) or frustrating (the material was unclear)?
- Which build project was most satisfying to complete?
- What would you change about the course structure or content?
Level 2 — Learning: What do you now know that you did not before?
This is where your self-assessment ratings matter. Compare your before and after scores. Beyond the numerical ratings, identify:
- Three concepts you can now explain to another developer that you could not before the course.
- Two techniques you can now implement from scratch without referring to documentation.
- One architecture pattern you can now design independently.
Level 3 — Behavior: What have you already applied to real work?
If you have already used any course skills in client or production work during the course period, note it here. Level 3 is about transfer — knowledge that moved from the course into real-world practice. Examples: "I added RAG to a client project," "I used extended thinking to improve a research workflow," "I used the agent pattern to automate a multi-step process."
Level 4 — Results: What business outcomes has this enabled?
Level 4 is often unmeasurable immediately after a course. Set a calendar reminder for 3 months and 6 months from now to revisit this question. By then, you will have data: new clients landed, features shipped, revenue from AI-powered products, time saved through automation.
Kirkpatrick Level 4 (Results) may be measurable 3–6 months after course completion. Set a calendar reminder to revisit your assessment at the 90-day and 180-day marks. By then, you will have concrete data on whether the skills from this course translated into business outcomes.
Remaining Gaps and Next Steps
This course covered the core skills of AI engineering. Several important topics were identified during course design as being out of scope for a 17-module program but critical for advanced practice. Here is where to go next for each identified gap.
Coverage Gap #1 — Fine-tuning hands-on
This course covered fine-tuning conceptually in Module 3 (LoRA, QLoRA, when to fine-tune vs RAG). For hands-on implementation, study the Hugging Face PEFT library and follow their LoRA fine-tuning tutorial. The fast.ai course covers the deep learning fundamentals that make fine-tuning approachable.
Coverage Gap #2 — Production observability
Monitoring AI applications in production requires specialized tooling beyond standard web observability. Explore Sentry AI monitoring for error tracking and AI-specific telemetry. Langfuse provides LLM tracing — the ability to trace a user request through your entire AI pipeline (retrieval, generation, tool calls) with token usage and latency at each step.
Coverage Gap #3 — Cost optimization at scale
When your application serves thousands of users, API costs become a primary concern. Study prompt caching (Anthropic and OpenAI both offer this), model routing (use cheaper models for simple tasks, expensive models for complex ones), and rate limiting patterns that protect your budget while maintaining quality of service.
Coverage Gap #4 — Prompt injection and security
Securing AI applications against adversarial inputs is an emerging discipline. Start with the OWASP LLM Top 10 (a catalog of the most common vulnerabilities in LLM applications), then read Anthropic's safety documentation for Claude-specific mitigations. The key areas are prompt injection, data exfiltration, and privilege escalation through tool calling.
Coverage Gap #5 — Streaming architecture
This course used Convex's reactive system for streaming. For deeper study, explore the differences between Server-Sent Events (SSE), WebSockets, and Convex reactive queries. Each has different tradeoffs for latency, connection management, and scalability. The Convex documentation on reactive queries is the best starting point.
Coverage Gap #6 — Model selection framework (deepening)
Module 2 introduced model selection (Haiku/Sonnet/Opus). To deepen this, build a benchmarking pipeline that evaluates models on your specific use case. Run the same prompts through different models, score the outputs (using LLM-as-Judge from Module 2), and build a decision matrix specific to your domain and quality requirements.
Recommended Next Resources
Papers
- "Attention Is All You Need" (Vaswani et al., 2017) — The original transformer paper. After Module 1, you have the background to read this and understand every section.
- "Scaling Laws for Neural Language Models" (Kaplan et al., 2020) — Why bigger models perform better, and the relationship between compute, data, and parameters.
- Snell et al. ICLR 2025 — The research on inference-time compute scaling that underpins the reasoning models from Part 4.
Anthropic resources
- Claude API reference — The complete API documentation for every feature you used in this course, plus features we did not cover.
- "Building Effective Agents" guide — Anthropic's official guidance on agent architectures, patterns, and best practices.
- Anthropic model card — Detailed documentation of Claude's capabilities, limitations, and safety characteristics.
Convex resources
- @convex-dev/agent documentation — Deep dive into the agent framework you used in Parts 3–5.
- @convex-dev/rag documentation — Advanced RAG patterns beyond what was covered in Module 4.
- @convex-dev/workflow documentation — Durable execution patterns for long-running AI tasks.
- Ian Macartney's blog posts — Practical patterns for building AI applications with Convex from one of the framework's core developers.
Community
- Anthropic Discord — Active community of Claude developers. Good for API questions and sharing patterns.
- Convex Discord — Direct access to Convex engineers for technical questions.
- Latent Space podcast — Interviews with AI engineers and researchers. Good for staying current with the field.
Advanced courses
- fast.ai — Deep learning fundamentals. This fills the gap between "using AI APIs" and "understanding the models at a deeper level." Covers training, fine-tuning, and deployment.
- Hugging Face NLP course — Hands-on fine-tuning of language models. The practical complement to the conceptual coverage in Module 3.
90-Day Continued Learning Plan

A course without follow-through fades. Here is a template for continuing your AI engineering growth over the next 90 days.
Month 1 — Apply course skills to a real project
Pick one of two paths:
- Client path: Identify a feature in an existing client project that could benefit from AI (RAG for documentation, agent for workflow automation, multimodal for content creation). Implement it using the patterns from this course. Ship it to production.
- Product path: Take your capstone project and develop it into a real product. Add authentication, improve the UI, handle edge cases, add monitoring. Deploy it and share the URL.
The goal for Month 1 is at least one real-world AI feature shipped to production.
Month 2 — Address top 2 identified gaps
From your self-assessment, identify the two lowest-scoring skill areas. Dedicate Month 2 to targeted study:
- If your gap is fine-tuning: Complete the Hugging Face PEFT tutorial. Fine-tune a small model on a custom dataset.
- If your gap is observability: Add Sentry and Langfuse to your Month 1 project. Set up dashboards for token usage, latency, and error rates.
- If your gap is security: Read the OWASP LLM Top 10. Audit your Month 1 project for prompt injection vulnerabilities.
- If your gap is cost optimization: Implement prompt caching and model routing in your Month 1 project. Measure the cost savings.
Month 3 — Contribute and teach
The best way to solidify knowledge is to share it. In Month 3, choose one of these contribution paths:
- Build an MCP server and publish it. Even a simple one (a domain-specific tool integration) contributes to the ecosystem and demonstrates your understanding of the protocol.
- Write a post-mortem on the AI feature you shipped in Month 1. Document what worked, what failed, what you would do differently. Publish it on your blog or LinkedIn.
- Teach a workshop based on one module from this course. Teaching forces you to understand the material at a deeper level than building does.
The best way to solidify what you learned is to teach it or ship it. Pick one for Month 1. If you ship an AI feature to production, you will learn more from debugging real-world issues in one week than from re-reading course material for a month.
Capstone Self-Assessment Rubric
Use this five-criteria rubric to evaluate the quality of your capstone project. Rate each criterion on a 1–5 scale.
A total score of 20/25 or higher indicates a strong portfolio piece. A score of 15–19 indicates a solid foundation that would benefit from polish. Below 15 suggests revisiting the architecture or scope.
Course Complete
You started this course as a TypeScript developer who used LLM APIs. You are finishing it as an AI engineer who understands the systems behind those APIs, can design and build production AI applications, and has six deployed projects to prove it.
The field is moving fast. Models will get better, APIs will change, new patterns will emerge. But the fundamentals you learned — how transformers work, how to build retrieval systems, how to design agents, how to reason about cost and quality, how to integrate multimodal capabilities — those are durable. They are the foundation on which everything else is built.
Keep building. Keep shipping. Keep learning.