Training and Post-Training
Understand how Claude got its capabilities — and when you should (and shouldn't) change them.
What you'll learn
Stage 1 — Pre-Training
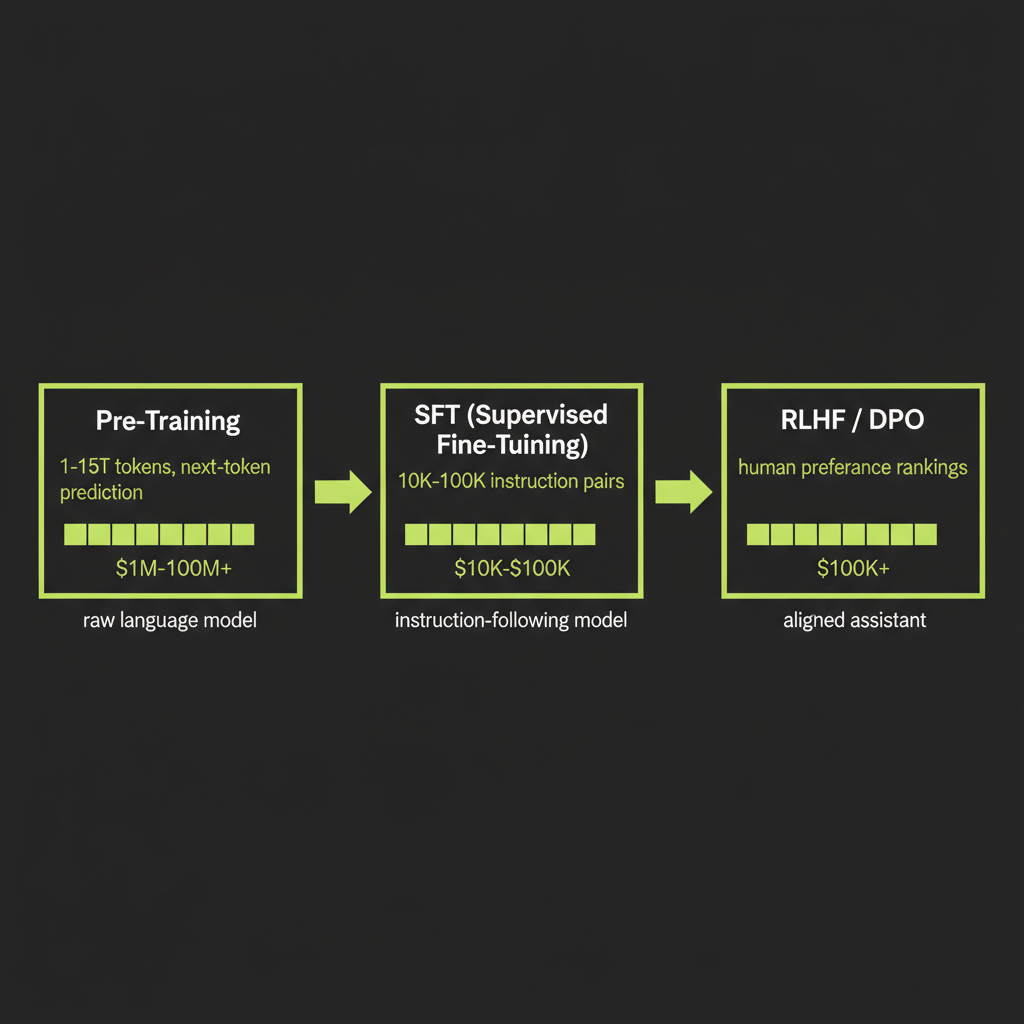
Pre-training is the foundation of every LLM. It is the stage where the model learns language, facts, reasoning patterns, and code — all from a single objective: predict the next token.
Next-token prediction on trillions of tokens
The training objective is deceptively simple. Given a sequence of tokens, predict the next one. Adjust the model's billions of parameters to minimize the prediction error. Repeat across 1–15 trillion tokens of training data.
Input: "The cat sat on the"
Target: "mat"
Loss = -log(P("mat" | "The cat sat on the"))
Repeat for 1-15 trillion examples, adjusting weights each time.The training data comes from a massive, carefully curated corpus: web crawls (Common Crawl, refined subsets), books, Wikipedia, academic papers, code from GitHub and StackOverflow. Data quality matters enormously — deduplication, toxicity filtering, and domain balancing are all critical preprocessing steps. "Garbage in, garbage out" operates at planetary scale during pre-training.
What pre-training produces
After pre-training, you have a base model — a powerful text completion engine that has absorbed world knowledge, language understanding, and the seeds of reasoning ability. But a base model is not yet a useful assistant. Ask it a question, and it might continue with another question instead of answering. It has learned to complete text, not to follow instructions.
- Can do: Complete text naturally, demonstrate knowledge (sometimes), write code (sometimes)
- Cannot do well: Follow instructions reliably, refuse harmful requests, have a conversation
Compute cost: why you will never pre-train a model
Pre-training a frontier model costs $1M–$100M+ in compute. This requires thousands of GPUs running for weeks or months. As an AI engineer using the Claude API, you will never pre-train a model — and that is fine. Your job is to make the most of the model that Anthropic has already trained. Understanding how it was trained helps you understand why it behaves the way it does.
Stage 2 — Supervised Fine-Tuning (SFT)
From a raw language model to an assistant
Supervised Fine-Tuning transforms the base model from a text completion engine into something that actually follows instructions. The training data is a curated set of (instruction, response) pairs — examples of what a helpful assistant should say:
Instruction: "Explain quantum computing in simple terms"
Response: "Quantum computing uses quantum bits (qubits) that can
exist in multiple states simultaneously, unlike classical
bits which are either 0 or 1. This allows quantum
computers to process certain problems much faster..."
Instruction: "Write a Python function to reverse a string"
Response: "def reverse_string(s: str) -> str:
return s[::-1]"10K–100K high-quality instruction-response pairs
SFT datasets are small compared to pre-training data, but they are extremely high quality. Each example is carefully written or curated to demonstrate the ideal assistant behavior. The model's massive pre-training knowledge is already there — SFT just teaches it the format of being helpful.
What SFT teaches — and what it does not
SFT is remarkably effective at teaching format, tone, and instruction following. After SFT, the model knows to answer questions rather than continuing them, to format code in code blocks, and to structure responses with headers and bullet points when appropriate.
What SFT cannot teach effectively is preferences, values, and nuanced tradeoffs. When a user asks a politically sensitive question, what is the "correct" response? When two values conflict (helpfulness vs. safety), how should the model balance them? These require a different approach.
Stage 3 — RLHF and DPO
Reinforcement Learning from Human Feedback
RLHF addresses the gap that SFT leaves: teaching the model preferences that are hard to specify as explicit rules. The process has three steps:
- Collect preference data: Show human evaluators two responses to the same prompt and ask which is better. Not "rate this 1–5," but "which of these two would you prefer?" This comparative approach is more reliable because humans are better at ranking than scoring.
- Train a reward model: Train a separate model to predict human preferences. Given a prompt and a response, the reward model outputs a score that estimates how much a human would prefer this response.
- Optimize with PPO: Use Proximal Policy Optimization to fine-tune the LLM to generate responses that the reward model rates highly, while staying close to the SFT model (to prevent reward hacking).
Prompt: "Write a poem about coding"
Response A: [creative, well-structured, specific] <- Human prefers this
Response B: [generic, repetitive, vague]
The reward model learns: Response A patterns = higher reward
The LLM is then optimized to produce more Response A patternsDPO: a simpler alternative
Direct Preference Optimization skips the reward model entirely. It directly optimizes the LLM using preference pairs — increasing the probability of preferred responses and decreasing the probability of rejected ones:
For each (prompt, preferred_response, rejected_response):
Increase probability of preferred_response
Decrease probability of rejected_responseDPO is simpler to implement, does not require a separate reward model, and produces more stable training. The tradeoff is that it may not capture extremely nuanced preferences as well as full RLHF. In practice, many recent models (including Claude) use DPO or related techniques as part of their post-training pipeline.
What post-training adds
The combination of SFT and RLHF/DPO produces the assistant behavior you see in production models: helpfulness, safety guardrails, refusal of harmful requests, and the nuanced judgment that makes Claude feel like a thoughtful collaborator rather than a text generator.
Coverage Gap #1 from the course analysis: fine-tuning is explained at the conceptual level in this module. Full build-level fine-tuning implementation is out of scope for this course — as an AI engineer using the Claude API, you will primarily work with prompting and RAG rather than training your own models.
Fine-Tuning in Practice (LoRA and QLoRA)
What fine-tuning changes: model weights, not just context
Fine-tuning modifies the model's internal weights to change its behavior permanently (or semi-permanently). Unlike prompting (which provides temporary context) or RAG (which retrieves external knowledge), fine-tuning changes how the model thinks at the parameter level.
This is powerful but comes with significant tradeoffs: it is expensive, requires high-quality training data, and the changes are baked into the model. You cannot easily update fine-tuned knowledge — you would need to re-train.
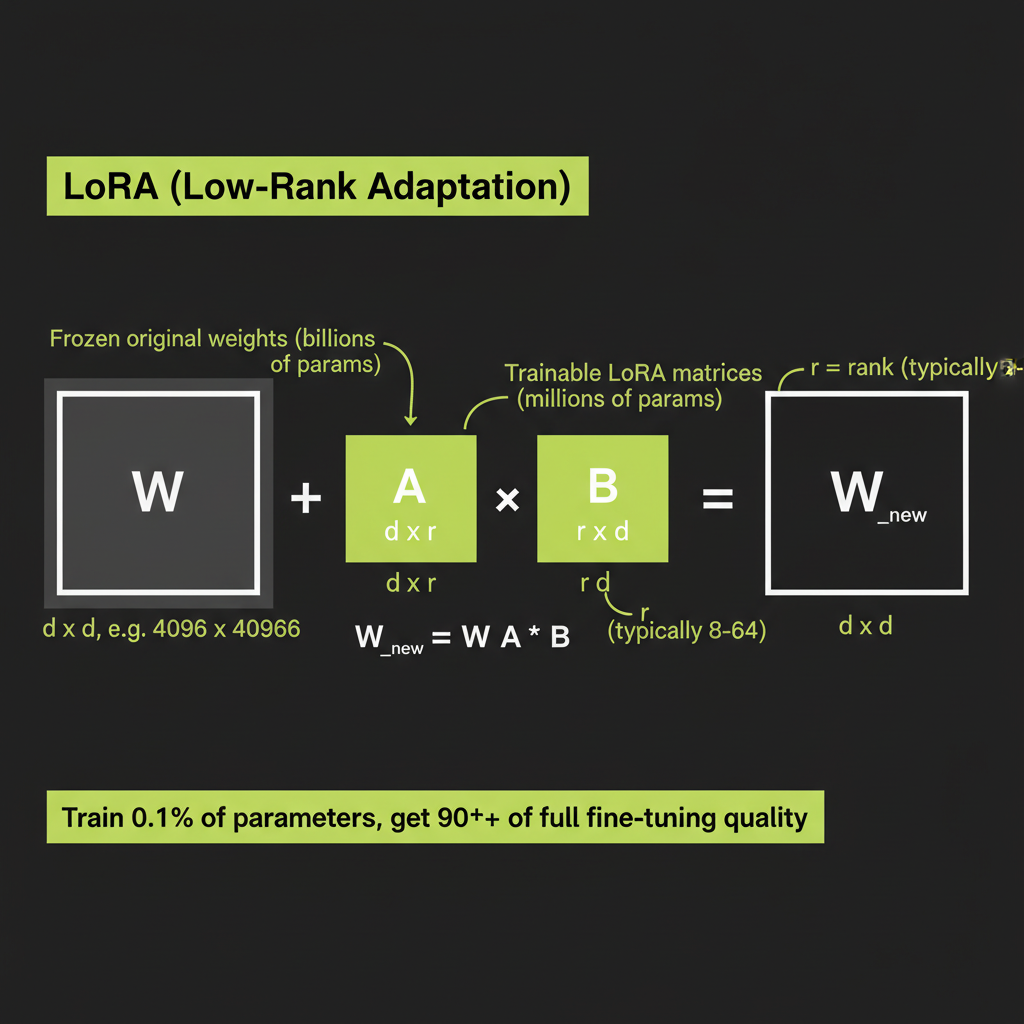
LoRA: low-rank adaptation
LoRA (Low-Rank Adaptation) makes fine-tuning practical by dramatically reducing the number of parameters you need to train. Instead of modifying all of the model's weights, LoRA freezes the original weights and adds small, low-rank matrices alongside them:
Original weight matrix W: 4096 x 4096 = 16.7M parameters
LoRA decomposition:
Matrix A: 4096 x 16 = 65,536 parameters
Matrix B: 16 x 4096 = 65,536 parameters
Total trainable: 131,072 parameters (0.8% of original)
During inference:
output = x * W + x * A * B
(original weights frozen, only A and B are trained)The "rank" in "low-rank" refers to the inner dimension (16 in this example). Lower rank means fewer parameters and faster training, but less expressive power. Rank 8–32 covers most practical use cases.
QLoRA: fine-tune on consumer hardware
QLoRA takes LoRA further by quantizing the frozen base model weights to 4-bit precision. This reduces memory requirements by 4x, making it possible to fine-tune a 70B-parameter model on a single GPU with 48GB of VRAM. The LoRA adapter matrices remain at full precision, so fine-tuning quality is preserved while the memory footprint shrinks dramatically.
Fine-tuning is expensive and rarely the right first choice. Before reaching for fine-tuning, exhaust prompting and RAG. Fine-tuning a model costs hundreds to thousands of dollars, requires curating high-quality training data, and produces a model that is harder to update than a RAG pipeline. The vast majority of production AI features do not require fine-tuning.
The Decision Framework: Prompting → RAG → Fine-Tuning
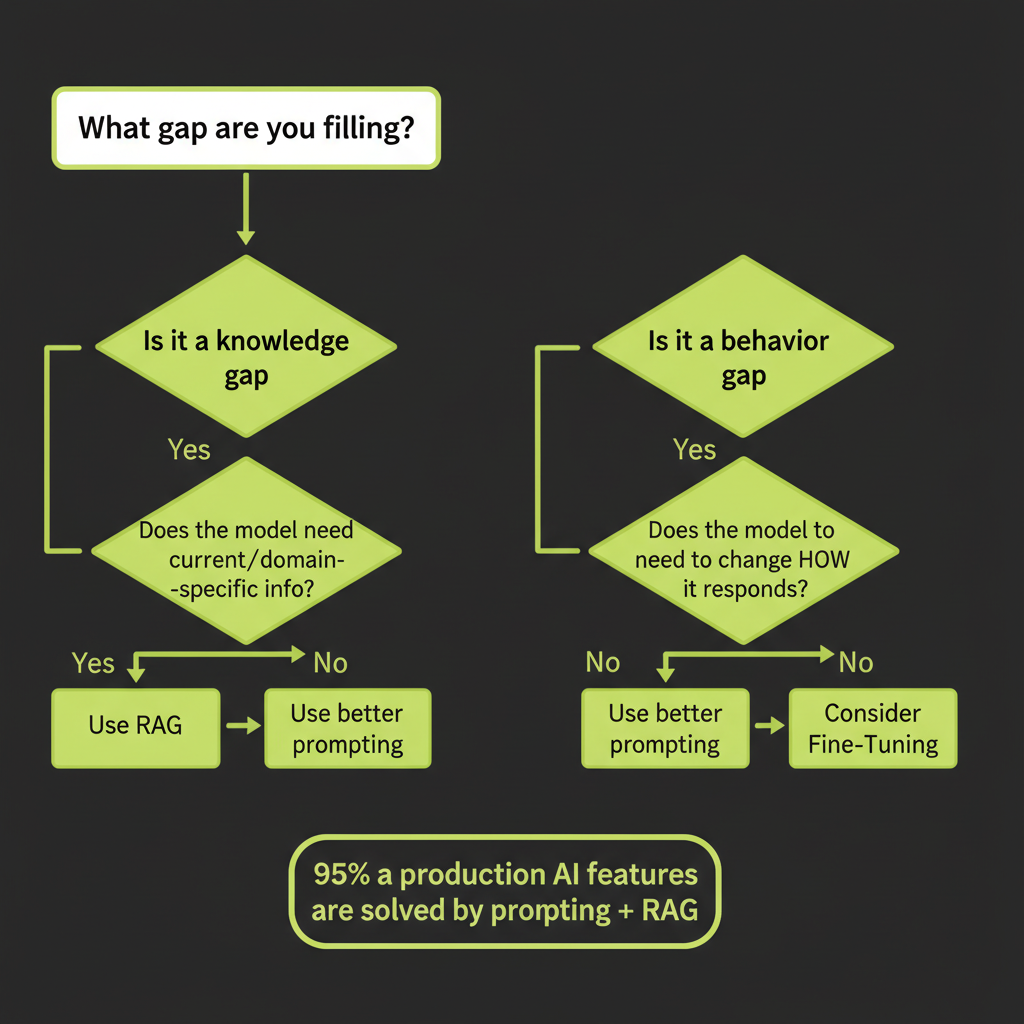
The golden rule
"Start with prompting. Add RAG when you need external knowledge. Fine-tune when you need to change behavior, not knowledge."
This is the single most important decision framework in this course. It prevents you from over-engineering solutions and guides you to the simplest approach that works.
Decision matrix: knowledge gap vs behavior gap vs capability gap
Gap Type | Example | Solution
Knowledge gap | "Answer questions about our docs" | RAG (retrieve, don't retrain)
Behavior gap | "Always respond in formal Japanese" | Fine-tuning (change model behavior)
Capability gap | "Reason about protein folding" | Bigger model or specialized model
Context gap | "Follow these 20 rules" | System prompt (provide rules at runtime)
Consistency gap | "Always output valid JSON" | Few-shot examples + structured outputThe misconception: "Fine-tuning is always better than RAG"
This is one of the most common mistakes AI engineers make. Fine-tuning adds knowledge by baking it into model weights — but this knowledge cannot be updated without retraining. RAG retrieves knowledge dynamically from an external source — you can update documents without touching the model.
Consider a customer support system that needs to answer questions about your product. Fine-tuning the model on your documentation means every product update requires retraining. RAG means you just update the documents in your vector store. For knowledge that changes frequently — which is most real-world knowledge — RAG wins decisively.
Approach | Best For | Update Cost | Data Needed
Prompting | General tasks, small context| Free | None
RAG | Dynamic knowledge, factual | Low (update docs) | Documents
Fine-tuning | Behavior change, style | High (retrain) | 1K-100K examples
Combined | Production systems | Medium | Both95% of production AI features are solved by prompting + RAG, not fine-tuning. If you are reaching for fine-tuning before you have tried a well-structured system prompt with few-shot examples and a RAG pipeline, you are almost certainly over-engineering the solution.
For each of the following scenarios, classify whether the solution is prompting only, RAG, or fine-tuning. Write a one-sentence justification for each.
- Customer support chatbot that answers questions about your product using your documentation. Product updates happen weekly.
- Legal document reviewer that identifies clauses in contracts and flags risks. Uses standard legal terminology.
- Code generation assistant that writes TypeScript functions from natural language descriptions.
- Brand voice writer that produces marketing copy matching your company's distinctive tone, vocabulary, and sentence structure.
- Factual Q&A system that answers questions about recent events (last 7 days).
Reference answers: (1) RAG — knowledge changes weekly, (2) Prompting + few-shot — standard task with examples, (3) Prompting — Claude already excels at this, (4) Fine-tuning — behavior/style change, (5) RAG — dynamic, recent knowledge needed.