Agentic Patterns
Five patterns from Anthropic's framework — learn to recognize them and choose the right one.
What you'll learn
Why Patterns Matter
Patterns encode accumulated engineering wisdom
When you see the same architecture solve the same category of problem across dozens of production systems, that architecture becomes a pattern. Patterns are not theoretical abstractions — they are battle-tested solutions that encode the lessons learned by engineers who built, shipped, debugged, and iterated on real systems.
Pattern recognition speeds design decisions
When a new task lands on your desk, pattern recognition lets you skip the "how do I architect this?" phase and jump to "which proven architecture fits this problem?" Instead of designing from scratch, you select, adapt, and implement. This is why senior engineers move faster — they have a larger library of patterns to draw from.
The 5 Anthropic patterns cover ~90% of production agentic use cases
Anthropic's "Building Effective Agents" paper describes five patterns that, in combination, cover the vast majority of production AI systems. Learning these five patterns gives you a design toolkit sufficient for almost any agentic task you will encounter.
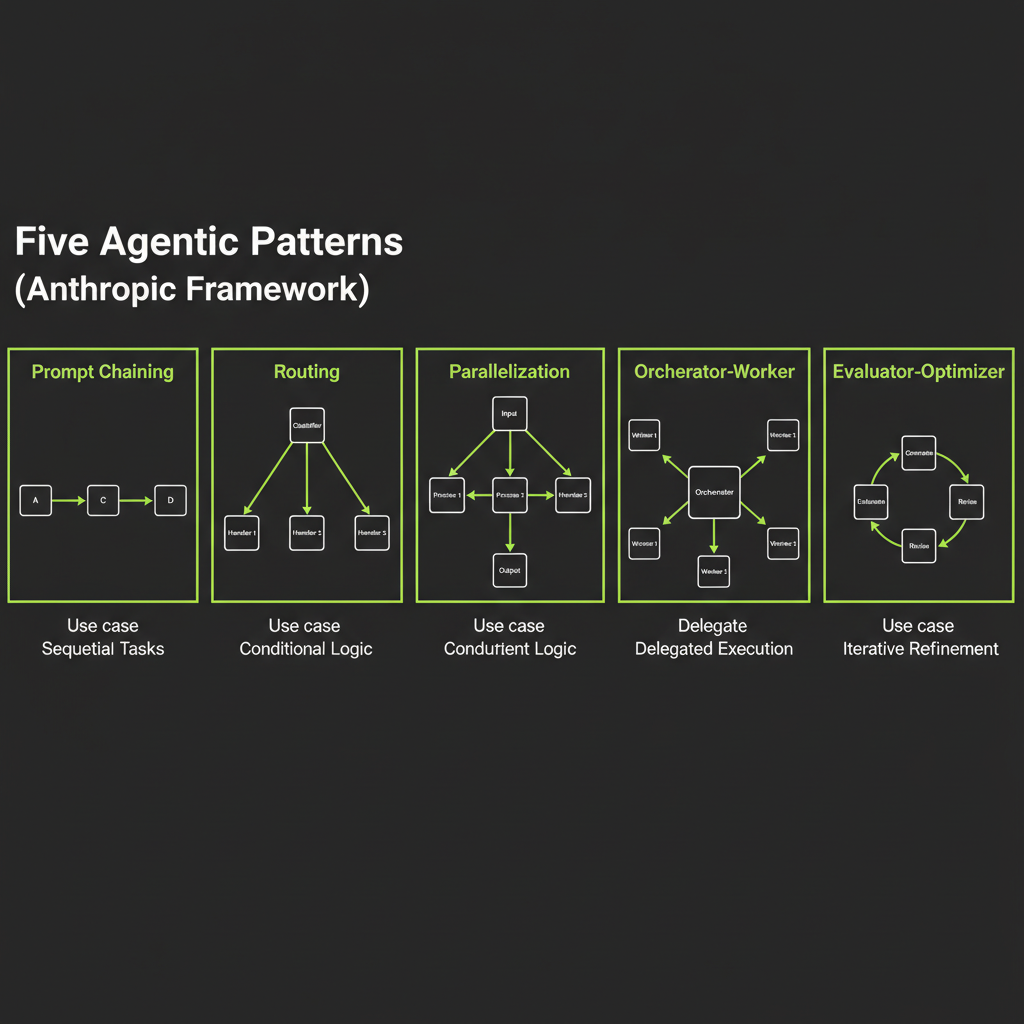
Pattern 1 — Prompt Chaining
Fixed sequential steps with quality gates between them
Prompt chaining breaks a complex task into a fixed sequence of LLM calls, where each step's output feeds the next step's input. Between each step, a quality gate validates the output before proceeding.
Input --> LLM (draft outline) --> Gate (has 3-5 sections?)
--> LLM (expand sections) --> Gate (word count OK?)
--> LLM (edit for tone) --> OutputWhen to use: task decomposes into predictable ordered steps
Prompt chaining works when you know the steps at design time and they always execute in the same order. Blog post generation (outline, expand, edit), document processing (extract, validate, transform), and translation pipelines (translate, verify, format) are all prompt chaining territory.
Gate design: validate output before proceeding
Gates are programmatic checks — not LLM calls. They validate that the previous step produced usable output: Does the outline have the right number of sections? Is the word count within range? Does the extracted JSON parse correctly? Gates catch errors early before they compound through subsequent steps.
Code pattern: sequential await chain with intermediate validation
// Prompt chaining with gates
const outline = await generateOutline(topic);
// Gate 1: validate outline structure
if (outline.sections.length < 3 || outline.sections.length > 5) {
throw new Error("Outline must have 3-5 sections");
}
const expanded = await expandSections(outline);
// Gate 2: validate word count
const wordCount = expanded.split(/\s+/).length;
if (wordCount < 500 || wordCount > 2000) {
throw new Error(`Word count ${wordCount} out of range`);
}
const final = await editForTone(expanded, targetTone);Pattern 2 — Routing
Classify input then route to specialized handler
Routing uses a fast classification step to determine the input type, then routes to a specialized handler optimized for that type. Each handler can have its own system prompt, tools, model, or even architecture.
Input --> LLM (classify) --> Router
|-- Handler A (billing questions)
|-- Handler B (technical support)
|-- Handler C (general inquiry)When to use: input type determines handling strategy
Routing is the right pattern when different categories of input need fundamentally different processing. Customer support (billing vs. technical vs. general), document processing (PDF vs. image vs. text), and content moderation (text vs. image vs. video) all benefit from routing.
Router design: fast, cheap classification model + specialized downstream handlers
The router itself should be simple and fast. For well-defined category sets, classification is one of the easiest tasks for LLMs — you can often use a smaller, cheaper model for the routing step. The specialized handlers downstream can be more expensive and more capable, since they only process inputs they are optimized for.
Routing works well for well-defined category sets. On ambiguous or out-of-category input, routing can fail silently — sending a request to the wrong handler with no indication that the classification was uncertain. Always add a fallback handler for inputs that do not fit any category cleanly.
Pattern 3 — Parallelization
Run multiple LLM calls simultaneously
Parallelization runs multiple LLM calls at the same time and aggregates the results. This is useful when subtasks are independent and can be processed without waiting for each other.
Sectioning variant: split document by section, process each in parallel, merge
Sectioning divides a task into independent subtasks based on the input structure. Each subtask runs in parallel, and the results are merged at the end:
// Sectioning: parallel code review
const [securityReview, perfReview, styleReview] = await Promise.all([
reviewForSecurity(codebase),
reviewForPerformance(codebase),
reviewForStyle(codebase),
]);
const combined = mergeReviews(securityReview, perfReview, styleReview);Voting variant (self-consistency): generate N outputs, take majority vote
Voting runs the same task N times and selects the most common answer. This improves reliability for tasks where individual LLM calls might make errors:
// Voting: content moderation with majority vote
const verdicts = await Promise.all([
moderateContent(input),
moderateContent(input),
moderateContent(input),
]);
const isSafe = verdicts.filter((v) => v === "safe").length >= 2;When sectioning wins vs when voting wins
Sectioning wins when the task naturally splits into independent parts: multi-section documents, multi-language translations, multi-aspect reviews. Each subtask is different, and the results are complementary.
Voting wins when you need higher accuracy on a single judgment: content moderation, classification, and fact-checking. Each subtask is identical, and the results are redundant by design.
Cost consideration: N parallel calls = N times cost
Parallelization is not free. Three parallel calls cost three times as much as one sequential call. Use parallelization when the reliability or speed improvement justifies the cost multiplication.
Pattern 4 — Orchestrator-Worker
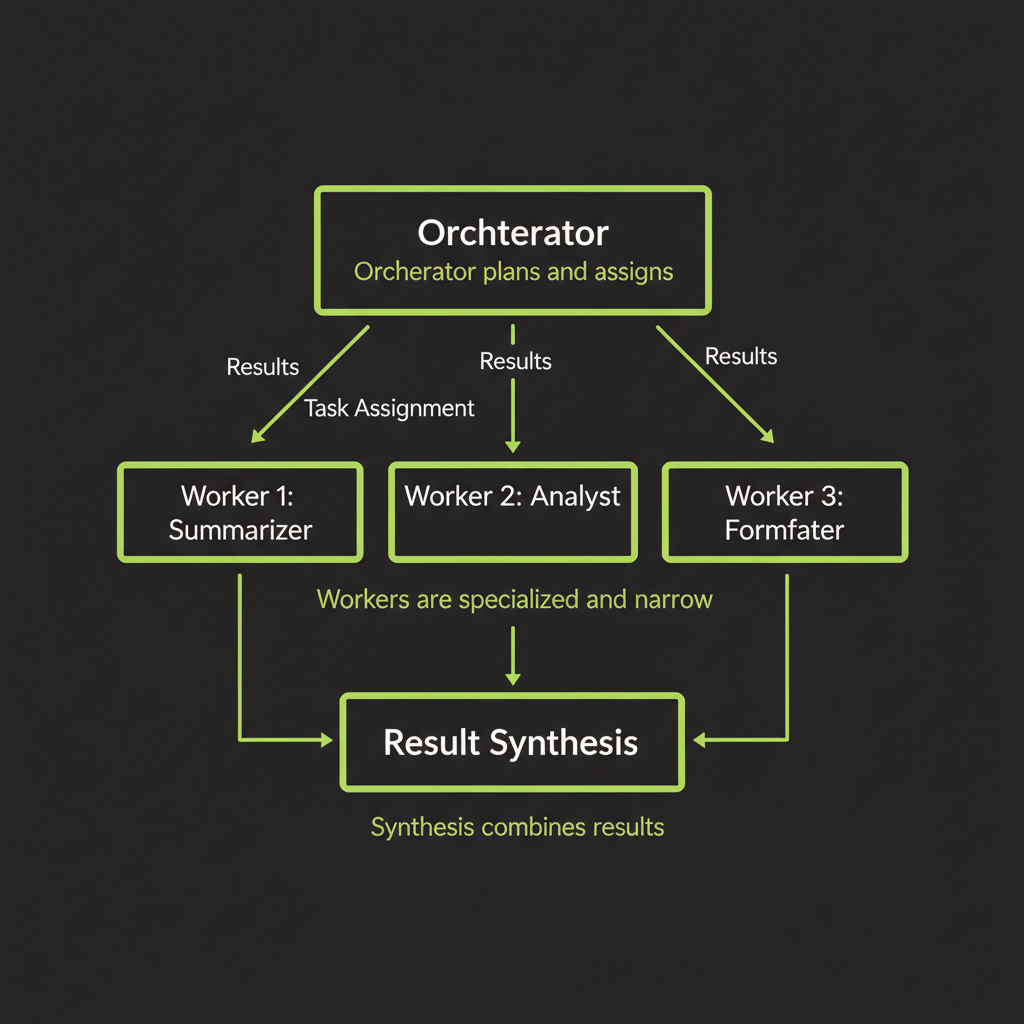
Central LLM dynamically assigns subtasks to worker agents
The orchestrator-worker pattern uses a central LLM (the orchestrator) to analyze the input, decide what subtasks are needed, assign them to specialized workers, and synthesize the results. Unlike prompt chaining, the subtasks are not known at design time — the orchestrator determines them at runtime.
When to use: task decomposition depends on input content
"Refactor this codebase to use the new API" — which files need changes? The orchestrator must read the code first to determine the answer. "Research and summarize this company" — which aspects to investigate? The orchestrator must understand the company first. Whenever the subtask list depends on analyzing the input, orchestrator-worker is the right pattern.
Orchestrator design: receives task, plans, assigns to workers, synthesizes results
// Orchestrator-worker pattern (conceptual)
const plan = await orchestrator.plan(task);
// plan: [
// { worker: "security", task: "Review auth.ts for vulnerabilities" },
// { worker: "refactor", task: "Update api.ts to use new SDK" },
// { worker: "test", task: "Add tests for the new API calls" },
// ]
const results = await Promise.all(
plan.map((item) => workers[item.worker].execute(item.task))
);
const synthesis = await orchestrator.synthesize(results);Worker design: specialized, narrow scope, reliable output format
Each worker should do one thing well. Workers have focused system prompts, limited tool sets, and strict output formats. A security review worker only reviews for security issues. A refactoring worker only refactors code. Narrow scope makes workers more reliable and their outputs easier to aggregate.
Multi-agent considerations: communication protocol, result aggregation
Orchestrator-worker systems require decisions about how agents communicate (shared context vs. isolated), how results are aggregated (merge vs. chain vs. select), and how errors propagate (fail one worker vs. fail all). These decisions dominate the complexity of the system.
Pattern 5 — Evaluator-Optimizer (Reflection)
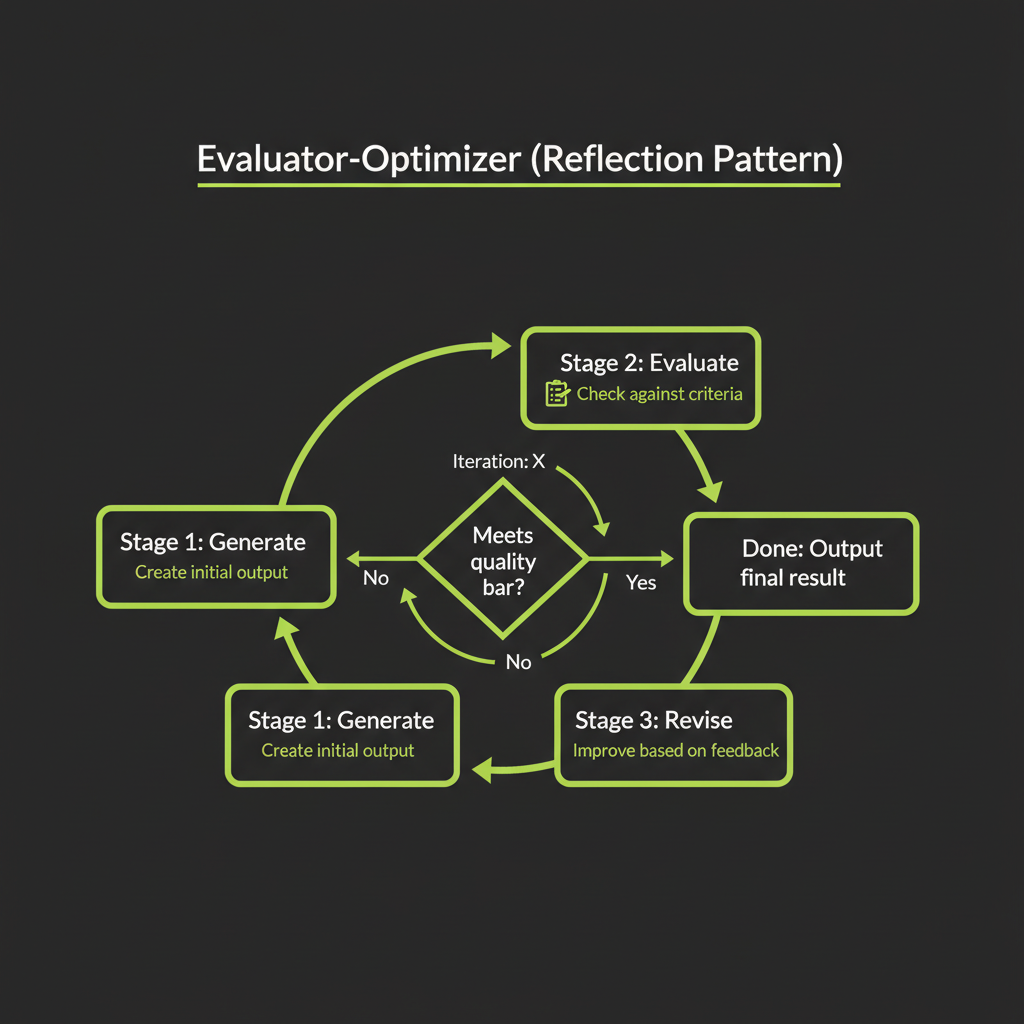
Generate → evaluate → revise loop
The evaluator-optimizer pattern uses two LLM roles: a generator that produces output and an evaluator that critiques it. The loop continues until the output meets quality criteria or hits an iteration limit.
Input --> Generator LLM --> Output Draft
^ |
| v
+-- Evaluator LLM (feedback) --+
(loop until good enough)When to use: task benefits from iterative refinement
Use this pattern when you have clear evaluation criteria and the task genuinely improves with iteration. Code that must pass unit tests, writing that must match a style guide, designs that must meet accessibility criteria. The evaluator provides specific, actionable feedback that guides the generator toward a better output.
Evaluator design: structured critique with specific improvement instructions
The evaluator should return structured feedback, not just "good" or "bad." Specify what is wrong, where it is wrong, and how to fix it. This gives the generator enough information to make meaningful improvements on the next iteration.
// Evaluator returns structured feedback
const evaluation = await evaluate(draft);
// {
// pass: false,
// issues: [
// { location: "paragraph 2", issue: "Passive voice", fix: "Rewrite in active voice" },
// { location: "conclusion", issue: "Missing CTA", fix: "Add call-to-action" },
// ]
// }Stopping condition: pass/fail threshold vs iteration limit
Set both a quality threshold (evaluator says "pass") and an iteration limit (maximum 3 revisions). Without an iteration limit, the loop can spin indefinitely on edge cases. Three iterations is usually sufficient — if the output is not good enough after three rounds, the problem is likely in the prompt or tool design, not the number of attempts.
Pattern Selection Decision Framework
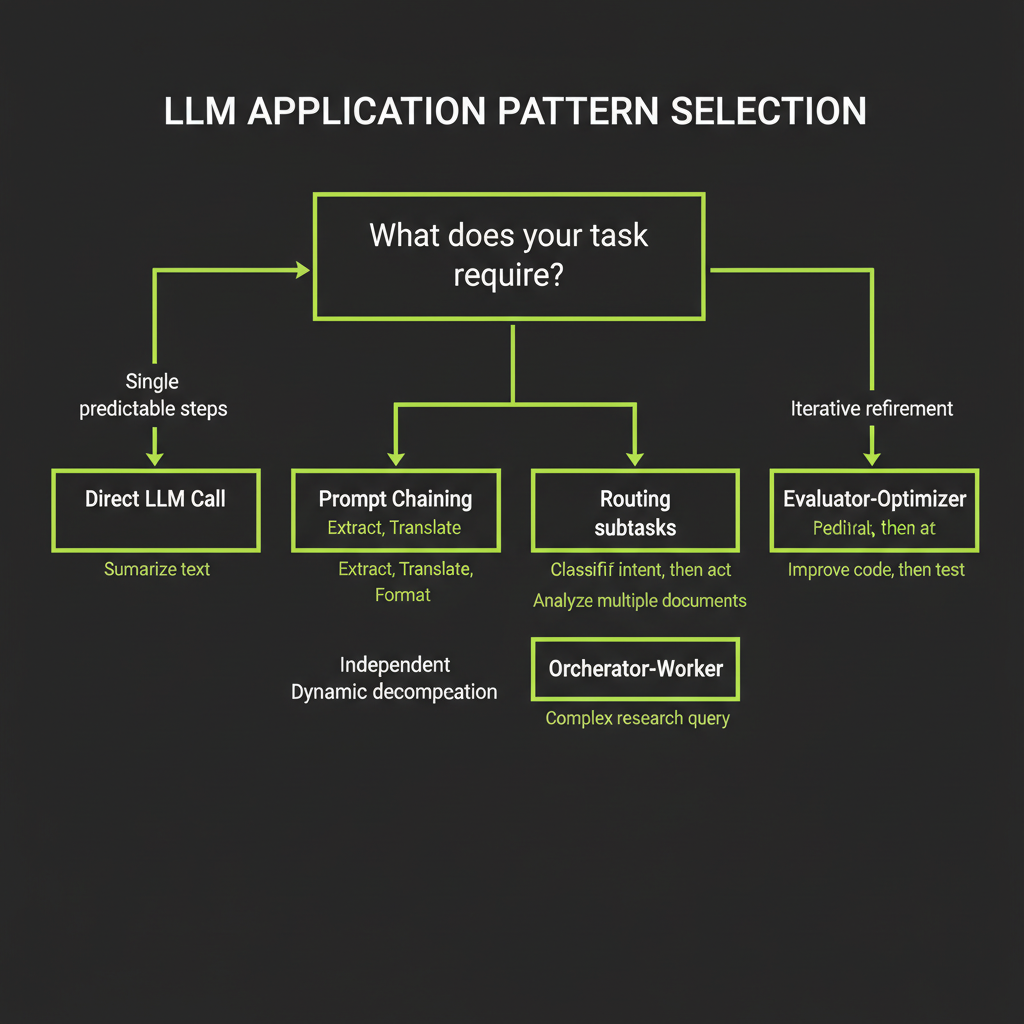
The decision tree with 6 branches
Is the task a single, well-defined transformation?
|-- YES --> Direct LLM call
|-- NO
|-- Are the steps predictable and sequential?
| |-- YES --> Prompt Chaining
| |-- NO
| |-- Does input type determine handling strategy?
| | |-- YES --> Routing
| | |-- NO
| | |-- Can subtasks run independently?
| | | |-- YES --> Parallelization
| | | |-- NO
| | | |-- Does task decomposition depend on input?
| | | | |-- YES --> Orchestrator-Worker
| | | | |-- NO --> Evaluator-OptimizerWalk through each branch with real examples
- "Translate this document to Spanish" → Single transformation → Direct LLM call
- "Generate a blog post: outline, write, edit" → Predictable sequential steps → Prompt Chaining
- "Triage this support ticket" → Input type determines handler → Routing
- "Review this code for security, performance, and style" → Independent subtasks → Parallelization
- "Refactor this codebase to use the new API" → Decomposition depends on input → Orchestrator-Worker
- "Write a function that passes these tests" → Benefits from iteration → Evaluator-Optimizer
This decision framework was created for this course. It is based on Anthropic's five agentic patterns with the "who decides" framing from Module 6 added as the organizing principle. The patterns themselves come from Anthropic's "Building Effective Agents" publication.
Multi-Agent Systems
When multiple agents are better than one: scope, specialization, reliability
Multi-agent systems use multiple specialized agents that coordinate on a task. They are useful when: a single agent's context window cannot hold all the information needed, different parts of the task require different tools or expertise, or you want to isolate failures so one bad agent does not corrupt the entire result.
Common multi-agent architectures
- Pipeline: Agent A's output feeds Agent B's input. Sequential, like prompt chaining but with autonomous agents at each step.
- Hub-and-spoke: A central orchestrator dispatches to specialist workers. This is the orchestrator-worker pattern with full agents instead of simple LLM calls.
- Peer-to-peer: Agents communicate directly with each other, without a central coordinator. Powerful but hard to debug.
Coordination challenges: state sharing, error propagation, cost amplification
Multi-agent systems multiply complexity in three dimensions. State sharing: how do agents pass information? Shared database, message passing, or context injection? Error propagation: if one agent fails, does the whole system fail? Can other agents compensate? Cost amplification: N agents means N times the token cost, plus coordination overhead. Use multi-agent systems only when a single agent with multiple tools genuinely cannot handle the task.
Start with the simplest pattern that works. A single agent with good tools handles 90% of use cases. Only reach for multi-agent when you have a clear reason: context overflow, specialization requirements, or failure isolation needs.
Classify the following five real-world tasks using the decision framework. Write the pattern name and a one-sentence justification for each.
- Translate a document to Spanish — Which pattern? Why?
- Answer questions about uploaded PDFs — Which pattern? Why?
- Review code for security issues — Which pattern? Why?
- Generate 3 marketing angles and pick the best — Which pattern? Why?
- Research and summarize a company — Which pattern? Why?
After classifying, compare your answers with a partner or check them against the decision tree above. Discuss any cases where multiple patterns could work and how you would choose between them.