Reasoning Models
Extended thinking changes what's possible — learn when to use it and how to configure it correctly.
What you'll learn
What Changes with Extended Thinking
In previous modules, we built agents that call tools reactively — the model sees a question, picks a tool, uses the result. Now the model thinks before it acts. That distinction changes everything.
Standard LLMs generate tokens left-to-right, one at a time, with no backtracking. They commit to the first approach that seems plausible. Reasoning models spend additional compute at inference time to explore multiple approaches, check their own work, and revise before giving you a final answer.
The key insight is fundamental: more compute at inference time = better answers for complex tasks. Instead of making the model bigger (training-time scaling), you let it think longer (inference-time scaling). This is a design decision you will make for every feature you build.
Thinking tokens vs output tokens: two separate budgets
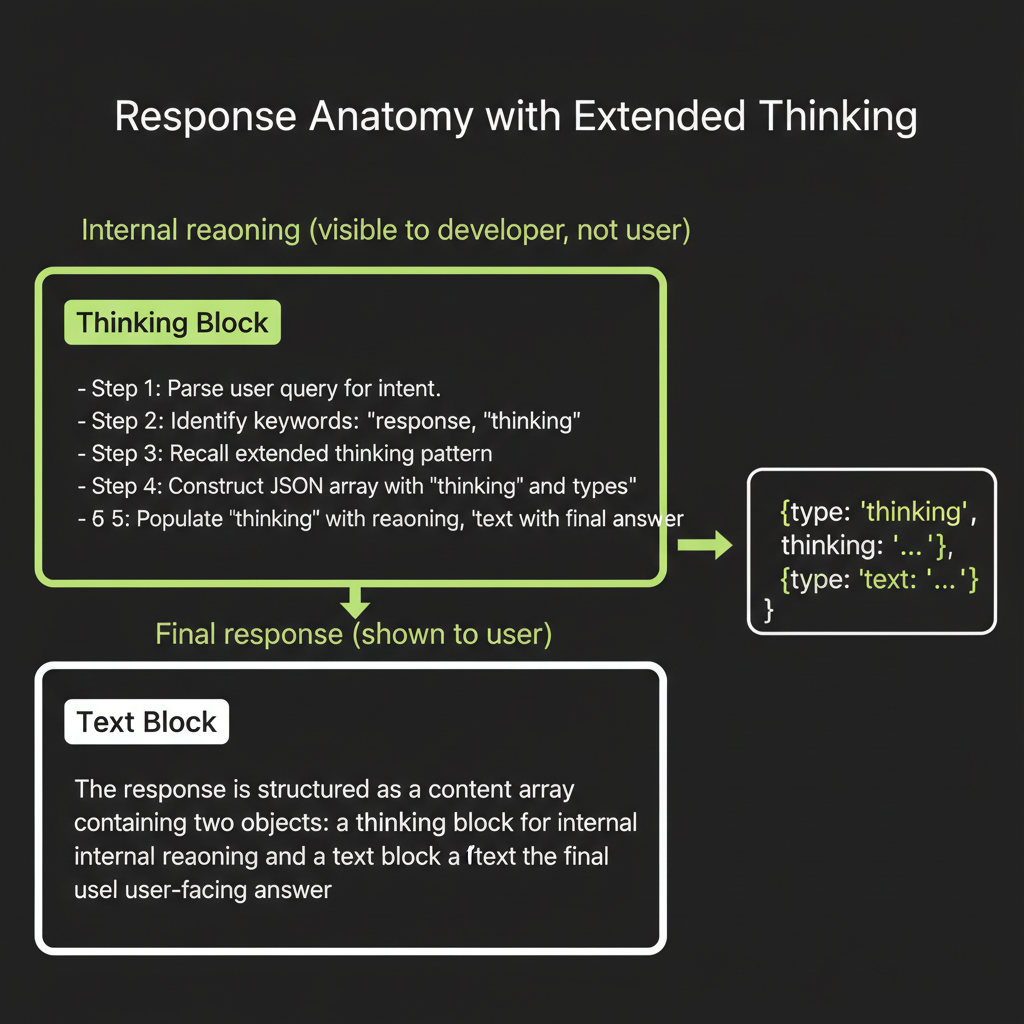
When extended thinking is enabled, Claude generates two types of content in its response. First, a thinking block containing the model's internal reasoning — exploring approaches, checking its work, considering edge cases. Second, the standard text block containing the final answer the user sees. Both consume tokens, and both count toward your bill.
The thinking block is visible to the developer through the API response. You can read it, log it, and use it for debugging. But the end user typically sees only the final polished answer. This gives you transparency into the model's reasoning process without cluttering the user experience.
Why extended thinking improves hard problems
Consider a task like synthesizing three contradictory sources on a topic. A standard model generates its response token by token, committing early to a narrative direction. If the first source it considers creates a frame, later sources get interpreted through that frame — even when they contradict it.
Extended thinking changes this. The model can explore multiple interpretive frames in its thinking block, weigh evidence from each source independently, notice contradictions explicitly, and then produce a balanced synthesis. The thinking tokens create "working memory" that the model can attend to — essentially letting it take notes before writing its final answer.
The Extended Thinking API
Enabling extended thinking
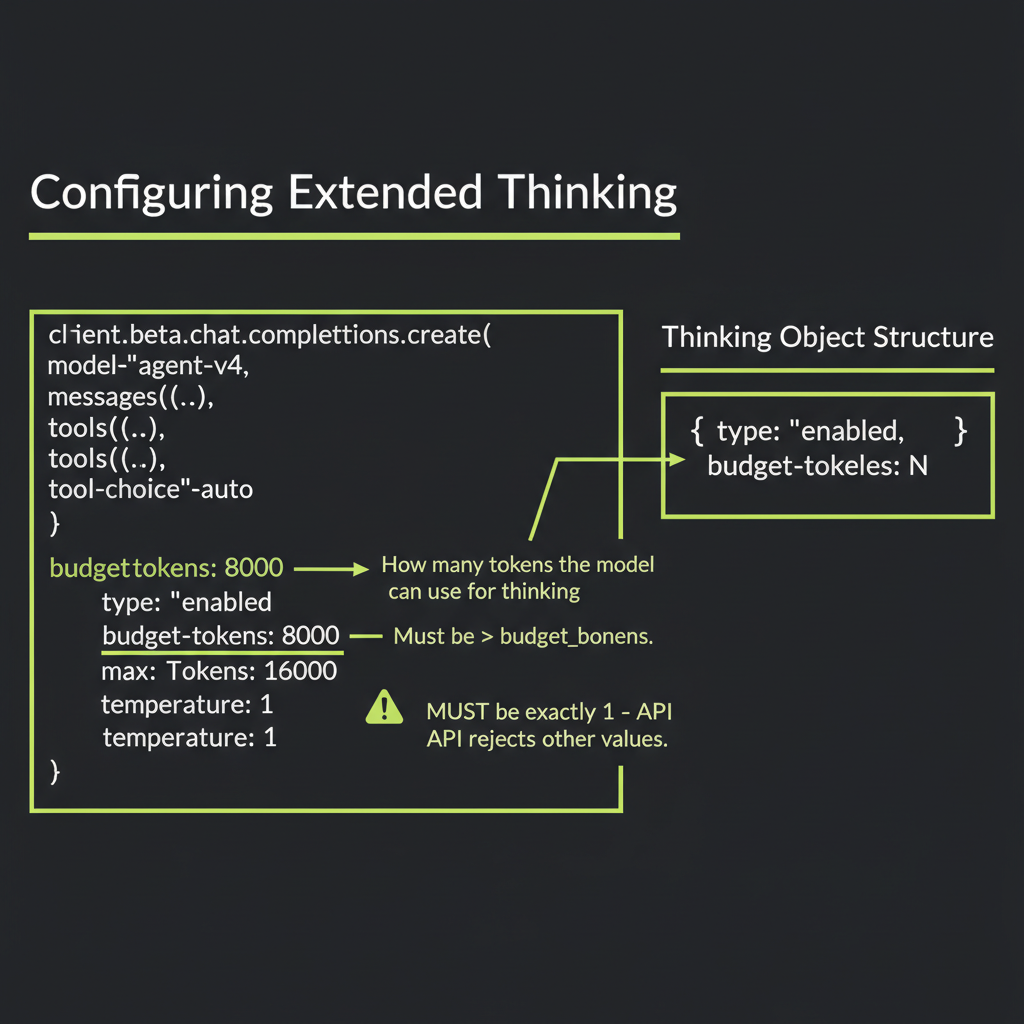
The API surface is straightforward. You add a thinking parameter to your message creation call:
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const response = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 16000,
thinking: {
type: "enabled",
budget_tokens: 10000, // up to 10k tokens for thinking
},
messages: [
{
role: "user",
content: "Analyze the tradeoffs between microservices and monoliths for a 5-person startup building a B2B SaaS product.",
},
],
});
// Response contains both thinking and text blocks
for (const block of response.content) {
if (block.type === "thinking") {
console.log("=== THINKING ===");
console.log(block.thinking);
} else if (block.type === "text") {
console.log("=== RESPONSE ===");
console.log(block.text);
}
}Critical constraints
Three constraints will bite you if you are not aware of them:
max_tokensmust be greater thanbudget_tokens. The budget comes out of the max_tokens allocation. Ifbudget_tokensis 10,000 andmax_tokensis 16,000, the model has up to 6,000 tokens for its visible response.- Temperature defaults to 1 and was historically required to be 1. Earlier versions of the API rejected any other value. Check the current API reference for the latest constraints, as Anthropic may have relaxed this requirement.
- Thinking tokens count toward your bill. Both thinking and response tokens are billed at the output token rate. A response with 8,000 thinking tokens + 2,000 response tokens costs as much as 10,000 output tokens.
Temperature was originally required to be 1 when using extended thinking. Check docs.anthropic.com for the latest constraints — these may evolve as the feature matures.
Streaming thinking tokens for progress indication
For real-time UX, stream the response. You can show a "thinking..." indicator while thinking tokens arrive, then display the actual response when it starts:
const stream = client.messages.stream({
model: "claude-sonnet-4-6",
max_tokens: 16000,
thinking: {
type: "enabled",
budget_tokens: 10000,
},
messages: [
{ role: "user", content: "Design a rate limiter for a distributed system." },
],
});
for await (const event of stream) {
if (event.type === "content_block_start") {
if (event.content_block.type === "thinking") {
console.log("[Thinking started...]");
} else if (event.content_block.type === "text") {
console.log("[Response started...]");
}
}
if (event.type === "content_block_delta") {
if (event.delta.type === "thinking_delta") {
// Show thinking progress (dot animation, spinner, etc.)
process.stdout.write(".");
} else if (event.delta.type === "text_delta") {
process.stdout.write(event.delta.text);
}
}
}Cost tracking: monitor the usage object
Always check usage to understand your costs. The output_tokens count includes both thinking and response tokens:
const response = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 16000,
thinking: { type: "enabled", budget_tokens: 10000 },
messages: [{ role: "user", content: complexQuestion }],
});
console.log("Input tokens:", response.usage.input_tokens);
console.log("Output tokens:", response.usage.output_tokens);
// Calculate cost using current rates from docs.anthropic.com/pricing
// Rates change with model updates -- never hardcode these in production.
// Example: look up per-million-token rates for your model, then:
// const inputCost = (response.usage.input_tokens / 1_000_000) * INPUT_RATE;
// const outputCost = (response.usage.output_tokens / 1_000_000) * OUTPUT_RATE;
// console.log(`Approximate cost: $${(inputCost + outputCost).toFixed(4)}`);Budget Token Tiers

How much thinking budget should you allocate? It depends on the task. Here is a four-tier framework for making that decision:
// Light reasoning — straightforward analysis
const lightConfig = {
thinking: { type: "enabled" as const, budget_tokens: 2000 },
max_tokens: 4000,
};
// Medium reasoning — multi-factor analysis, comparing options
const mediumConfig = {
thinking: { type: "enabled" as const, budget_tokens: 8000 },
max_tokens: 12000,
};
// Deep reasoning — synthesis of contradictory sources, complex planning
const deepConfig = {
thinking: { type: "enabled" as const, budget_tokens: 20000 },
max_tokens: 32000,
};
// Maximum reasoning — research synthesis, mathematical proofs
const maxConfig = {
thinking: { type: "enabled" as const, budget_tokens: 50000 },
max_tokens: 64000,
};The budget token tier table is a course-structured framework based on observed API behavior and practical testing, not Anthropic's official guidance. Start with 5,000–10,000 budget tokens for most tasks, then calibrate based on response.usage data. The model often uses less than the budget — it stops thinking when it has a good answer.
Practical calibration
The best approach is empirical. Start with a medium budget (8,000 tokens), run your task, and check how many thinking tokens were actually consumed. If the model consistently uses less than half the budget, you are over-allocating. If it hits the limit, try increasing the budget and comparing output quality.
For synthesis of 5–10 search results into a report, 10,000–20,000 budget tokens is typically the right range. For simple analysis of a single document, 2,000–5,000 is sufficient. For mathematical proofs or tasks with many interlocking constraints, 20,000–50,000 budget tokens can produce noticeably better results.
Reasoning Models in the Landscape
Extended thinking is Anthropic's approach to reasoning models, but it is not the only one. Understanding the landscape helps you evaluate tradeoffs and choose the right tool for each problem.
OpenAI o1/o3 series
OpenAI's o-series models were the first widely available reasoning models. They use chain-of-thought at scale — the model generates an internal reasoning trace before producing a final answer.
o1 (September 2024) was the proof of concept. Dramatically better at math, science, and coding benchmarks, but responses took 10–60 seconds because the model was generating thousands of internal reasoning tokens. o3 (early 2025) added a "reasoning effort" dial — low, medium, high — that lets you control how much thinking the model does. o4-mini (April 2025) proved that reasoning is not just about model size — it is about the inference-time computation pattern. A smaller model with the same reasoning architecture was surprisingly competitive at a fraction of the cost.
The key difference from Claude's approach: o-series internal thoughts are hidden from the developer by default. You pay for them but cannot read them. Claude's thinking blocks are visible and can be used for debugging.
DeepSeek-R1: open-weights reasoning via RL
DeepSeek-R1 took a different path. Instead of supervised fine-tuning for chain-of-thought, they used pure reinforcement learning to discover reasoning behaviors. They gave the base model math and logic problems with verifiable answers, rewarded correct final answers, and let RL discover whatever internal process produces correct results.
What emerged was striking. The model spontaneously learned to break problems into steps, check intermediate results, try alternative approaches when stuck, and allocate more thinking to harder problems. This showed that reasoning behavior can emerge from reward signals alone — you do not need hand-crafted chain-of-thought training data.
DeepSeek-R1 is open-weight, meaning you can run it locally. The reasoning tokens are visible (not hidden like o-series), which makes it a useful learning and debugging tool.
What they share
All reasoning models share a common insight: more compute at inference time produces better answers on hard problems. Training a bigger model is a one-time investment that improves all responses equally. Inference-time compute is an on-demand investment you apply selectively. As an AI engineer, you now have a new lever to pull — not just which model to use, but how much thinking to allocate.
PRMs vs ORMs

Reasoning models are trained and evaluated using reward models. Two paradigms dominate the field, and understanding them helps you reason about when and why reasoning models succeed or fail.
Outcome Reward Models (ORMs)
An ORM grades the final answer only. Did the model get the right answer? Yes or no. This is the simplest approach and works well for tasks with clear, verifiable answers — math problems, code that passes tests, factual questions with known answers.
The limitation: an ORM cannot tell you why the model got the right or wrong answer. A model might arrive at the correct answer through flawed reasoning (lucky guess), or produce incorrect answers despite mostly-correct reasoning (arithmetic error in the last step). ORMs cannot distinguish these cases.
Process Reward Models (PRMs)
A PRM grades each reasoning step individually. Is step 1 valid? Is step 2 logically sound given step 1? This provides a much richer training signal. The model learns not just to get the right answer but to reason correctly along the way.
The Snell et al. (ICLR 2025) paper found that PRMs outperformed ORMs on math and structured reasoning benchmarks in their study — evaluating intermediate reasoning steps was more effective than evaluating only the final answer for those task types. This is why chain-of-thought plus step-level evaluation tends to outperform answer-only evaluation for structured tasks.
PRM vs ORM comparison is task-dependent. The claim "PRMs always win" is an oversimplification. PRMs excel on math and structured reasoning where step validity is well-defined. For open-ended tasks like creative writing or subjective analysis, process evaluation is harder to define and the advantage diminishes.
When to Use Reasoning vs Standard Claude
Extended thinking is not free. Every thinking token costs money and adds latency. The decision framework is straightforward: if a smart person would need to "think hard" about the task, a reasoning model will outperform a standard one. If the task is more about knowledge retrieval than reasoning, save your tokens.
Worth the extra cost and latency
- Multi-step math and logic: Problems where showing work matters and the first intuition is often wrong.
- Synthesis of contradictory information: Resolving conflicts between multiple sources requires weighing evidence carefully.
- Code with complex edge cases: Reasoning about concurrency, error handling, and state management benefits from systematic exploration.
- Planning multi-step workflows: Designing agent architectures, research plans, or system designs.
- High-stakes decisions: Legal analysis, medical reasoning, financial modeling — tasks where errors are costly.
Not worth the cost
- Simple factual retrieval: "What is the capital of France?" does not benefit from thinking.
- Classification with clear categories: Sentiment analysis, intent routing, spam detection.
- Text formatting or transformation: Summarization, translation, reformatting.
- High-throughput pipelines: When latency is the bottleneck and you are processing thousands of requests.
- Creative writing: Thinking tokens do not improve creativity much — they improve reasoning.
If standard Claude gives inconsistent results on a task — sometimes great, sometimes wrong — try extended thinking. The consistency improvement is often worth the cost. If standard Claude is already >95% accurate, extended thinking adds cost without meaningful quality gain.
Run the same synthesis task using standard Claude and Claude with extended thinking to observe the quality difference firsthand.
- Choose a synthesis task — find 3 sources that present contradictory views on a topic (e.g., "Is microservices architecture better than monolithic for startups?").
- Run with standard Claude — send the 3 sources as context and ask for a synthesis. Record the response.
- Run with extended thinking — same prompt, but add
thinking: { type: "enabled", budget_tokens: 8000 }. Record both the thinking block and the response. - Compare — read the thinking block. Did the model consider more angles? Did it resolve contradictions more carefully? Does the extended thinking response address nuances the standard response missed?
- Check usage — log
response.usagefor both calls. Calculate the cost difference. Is the quality improvement worth the price?