Inference-Time Scaling
Trade compute for quality selectively — know which technique to reach for and when to stop.
What you'll learn
Why Inference-Time Scaling Matters
Training a bigger model is a one-time investment that improves all responses equally. Inference-time compute is an on-demand investment you apply selectively to hard problems. The "Scaling LLM Test-Time Compute Optimally" paper (Snell et al., ICLR 2025) showed something surprising: a smaller model with more inference-time compute can match or beat a larger model with less compute on certain benchmarks.
This has practical implications. You do not always need the biggest model — sometimes you need the smartest use of a model. And unlike training-time scaling (which requires Anthropic or OpenAI to train bigger models), inference-time scaling is something you control at the application level.
This module walks through five techniques, from simplest to most sophisticated, with real TypeScript implementations and clear cost/quality tradeoffs for each.
Technique 1 — Chain-of-Thought
Step-by-step reasoning via prompt
The simplest form of inference-time scaling. You ask the model to "think step by step" and it produces intermediate reasoning before the final answer:
Prompt: "How many r's are in 'strawberry'? Think step by step."
Response: "Let me go through each letter:
s-t-r-a-w-b-e-r-r-y
Position 3: r
Position 8: r
Position 9: r
There are 3 r's in 'strawberry'."Without CoT, models notoriously fail this kind of question. With CoT, they get it right because the intermediate tokens create "working memory" that the model can attend to. Each intermediate token becomes part of the context for generating the next token — the model is essentially writing notes to itself.
Cost and quality profile
Cost: ~1.3x (more tokens in the response, but no extra API calls). Quality gain: Significant for multi-step problems, minimal for simple generation. When to use: Any task where showing work helps — math, logic, multi-step analysis. It is nearly free because you just adjust your prompt.
Technique 2 — Self-Consistency (Majority Voting)
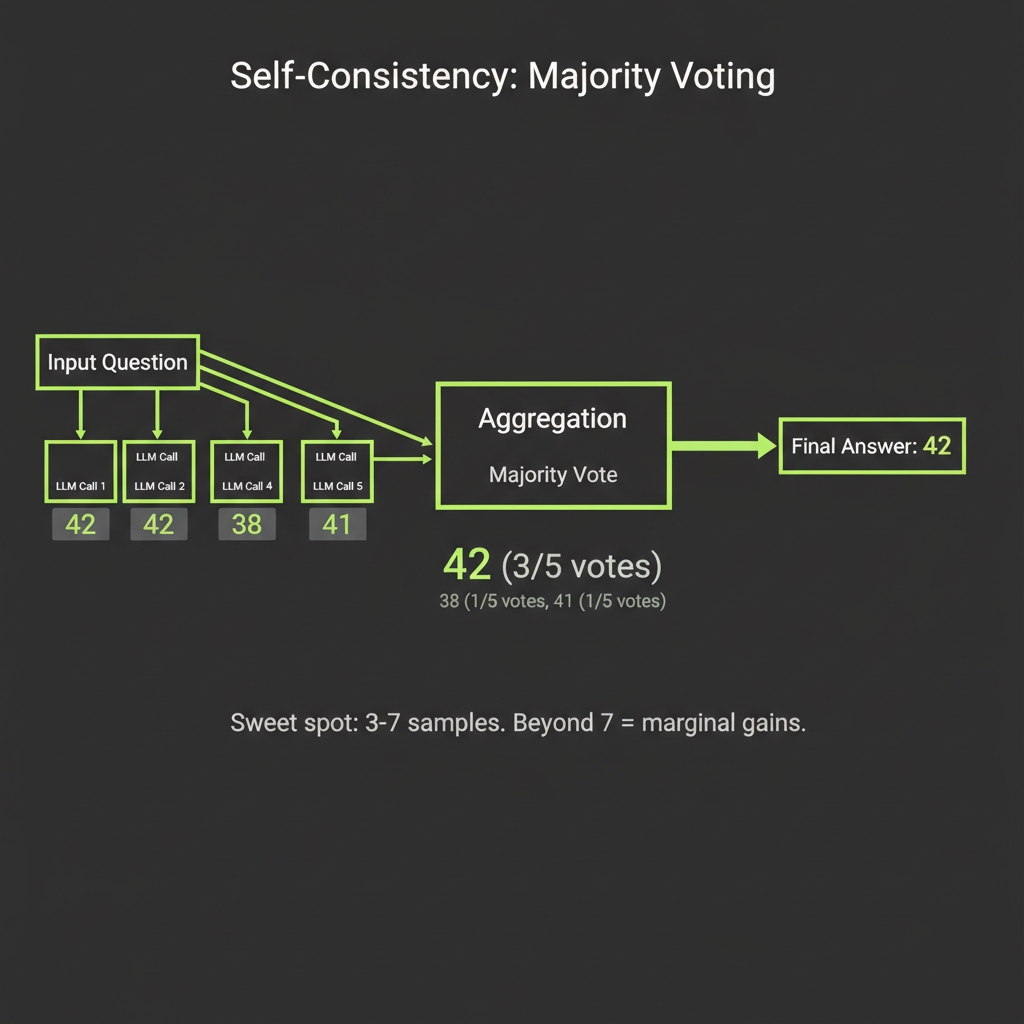
The approach: generate N, take the majority answer
Generate the same response N times with temperature > 0, then take the most common final answer. The insight is that correct reasoning paths are more likely than any specific incorrect path, so voting surfaces the right answer even if individual attempts sometimes fail.
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
async function selfConsistency(
prompt: string,
n: number = 5
): Promise<string> {
const responses = await Promise.all(
Array.from({ length: n }, () =>
client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 1024,
temperature: 0.7,
messages: [{ role: "user", content: prompt }],
})
)
);
// Extract final answers and vote
const answers = responses.map(r =>
extractAnswer(r.content[0].text)
);
const counts = new Map<string, number>();
for (const answer of answers) {
counts.set(answer, (counts.get(answer) ?? 0) + 1);
}
// Return the most common answer
return [...counts.entries()]
.sort((a, b) => b[1] - a[1])[0][0];
}
function extractAnswer(text: string): string {
// Extract the final numerical answer or conclusion
const match = text.match(/(?:answer|result|total).*?(\d+)/i);
return match ? match[1] : text.trim().split("\n").pop() ?? "";
}The sweet spot for self-consistency is 3–7 samples. Going from 1 to 5 samples gives large accuracy gains. Going from 5 to 50 gives marginal gains (Snell et al., ICLR 2025). Beyond 7 samples, you are paying for diminishing returns.
Cost and quality profile
Cost: N times base cost. 5 samples = 5x the cost. But all N calls run in parallel via Promise.all, so latency is the same as a single call. Quality gain: 10–30% improvement on math benchmarks in the research literature. When to use: Problems with clear correct answers — math, classification, factual questions.
Technique 3 — Sequential Revision
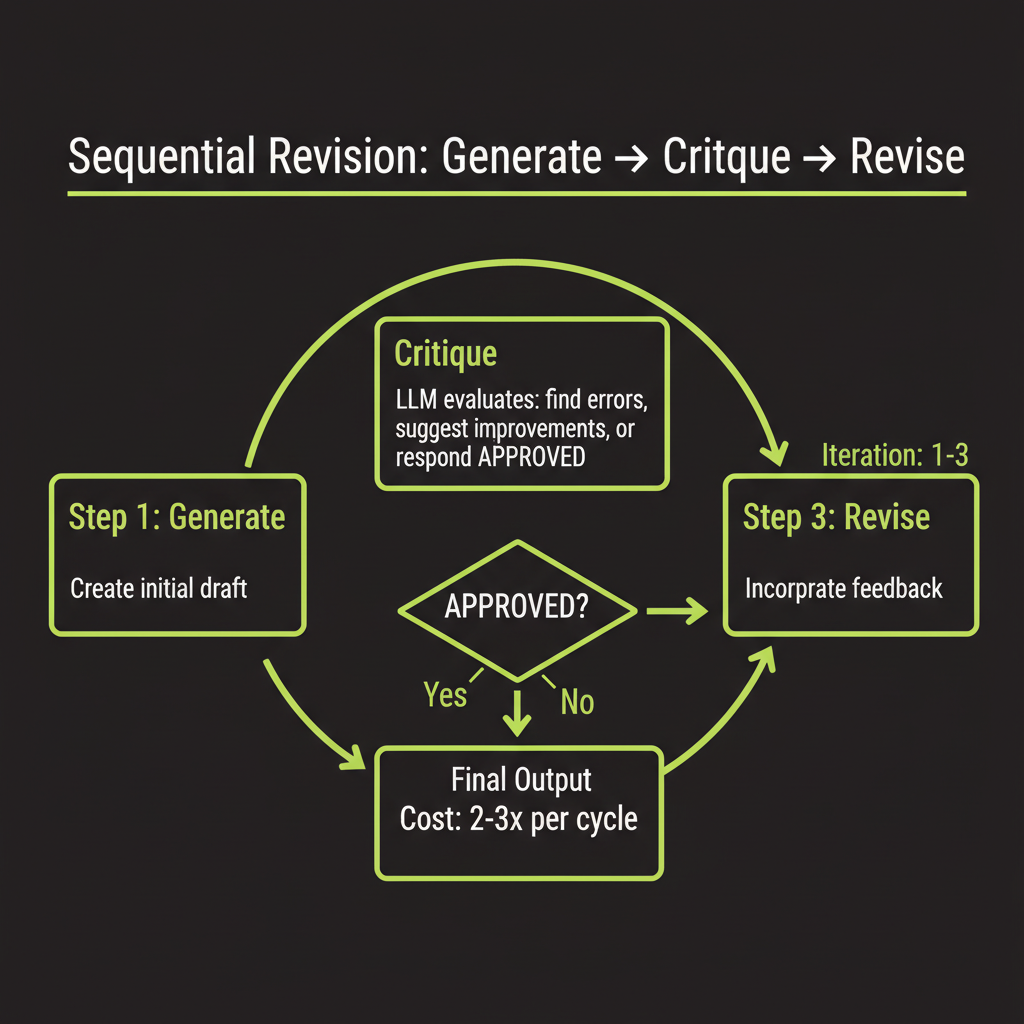
Generate, critique, revise
Instead of parallel samples, let the model critique and improve its own output iteratively. The loop continues until either the critic approves the answer or you hit a maximum iteration count:
async function sequentialRevision(
prompt: string,
maxRounds: number = 3
): Promise<string> {
let currentAnswer = await generate(prompt);
for (let i = 0; i < maxRounds; i++) {
const critique = await generate(
`Here is a question and an answer. Find any errors ` +
`or improvements.\n\n` +
`Question: ${prompt}\n\nAnswer: ${currentAnswer}\n\n` +
`If the answer is correct and complete, respond with ` +
`"APPROVED". Otherwise, provide the corrected answer.`
);
if (critique.includes("APPROVED")) break;
currentAnswer = critique;
}
return currentAnswer;
}Designing a quality threshold stopping condition
The naive approach uses a fixed iteration count. A better design uses a quality threshold — the critic evaluates on specific criteria and returns a score. You stop when the score exceeds your threshold:
interface CritiqueResult {
score: number; // 0-10 quality score
approved: boolean; // true if meets threshold
feedback: string; // specific improvement suggestions
}
async function revisionWithThreshold(
prompt: string,
threshold: number = 8,
maxRounds: number = 5
): Promise<string> {
let currentAnswer = await generate(prompt);
for (let i = 0; i < maxRounds; i++) {
const critique: CritiqueResult = await evaluateQuality(
prompt, currentAnswer
);
if (critique.approved || critique.score >= threshold) {
return currentAnswer;
}
currentAnswer = await generate(
`Improve this answer based on feedback:\n\n` +
`Original: ${currentAnswer}\n\n` +
`Feedback: ${critique.feedback}`
);
}
return currentAnswer;
}Cost and quality profile
Cost: 2–3x per revision cycle (sequential, so latency multiplies). Quality gain: Strong for writing, code generation, and analysis — tasks where quality improves with iteration. Less useful for pure math (self-consistency is better there). When to use: Quality-sensitive generation where you need the output to meet a standard.
Technique 4 — Best-of-N Sampling
Generate N candidates, pick the best
Generate N complete responses in parallel, then use a separate evaluation to pick the best one. Simpler than Tree of Thoughts but more effective than self-consistency for open-ended tasks where "most common" is not the same as "best":
async function bestOfN(
prompt: string,
n: number = 3,
evaluationCriteria: string
): Promise<string> {
// Generate N candidates in parallel
const candidates = await Promise.all(
Array.from({ length: n }, () =>
generate(prompt, { temperature: 0.8 })
)
);
// Use Claude to evaluate and rank
const evaluation = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 256,
messages: [{
role: "user",
content:
`Given these ${n} responses to "${prompt}", ` +
`rank them by: ${evaluationCriteria}. ` +
`Return ONLY the number (1-${n}) of the best.\n\n` +
candidates.map((c, i) =>
`--- Response ${i + 1} ---\n${c}`
).join("\n\n"),
}],
});
const bestIndex =
parseInt(evaluation.content[0].text.trim()) - 1;
return candidates[bestIndex];
}Cost and quality profile
Cost: (N + 1) times base cost — N generations plus 1 evaluation call. Latency is similar to a single call since generations run in parallel. Quality gain: Strong for creative and subjective tasks. When to use: Creative writing, code generation, anything where "best" is subjective and there is no single correct answer.
Technique 5 — Tree of Thoughts
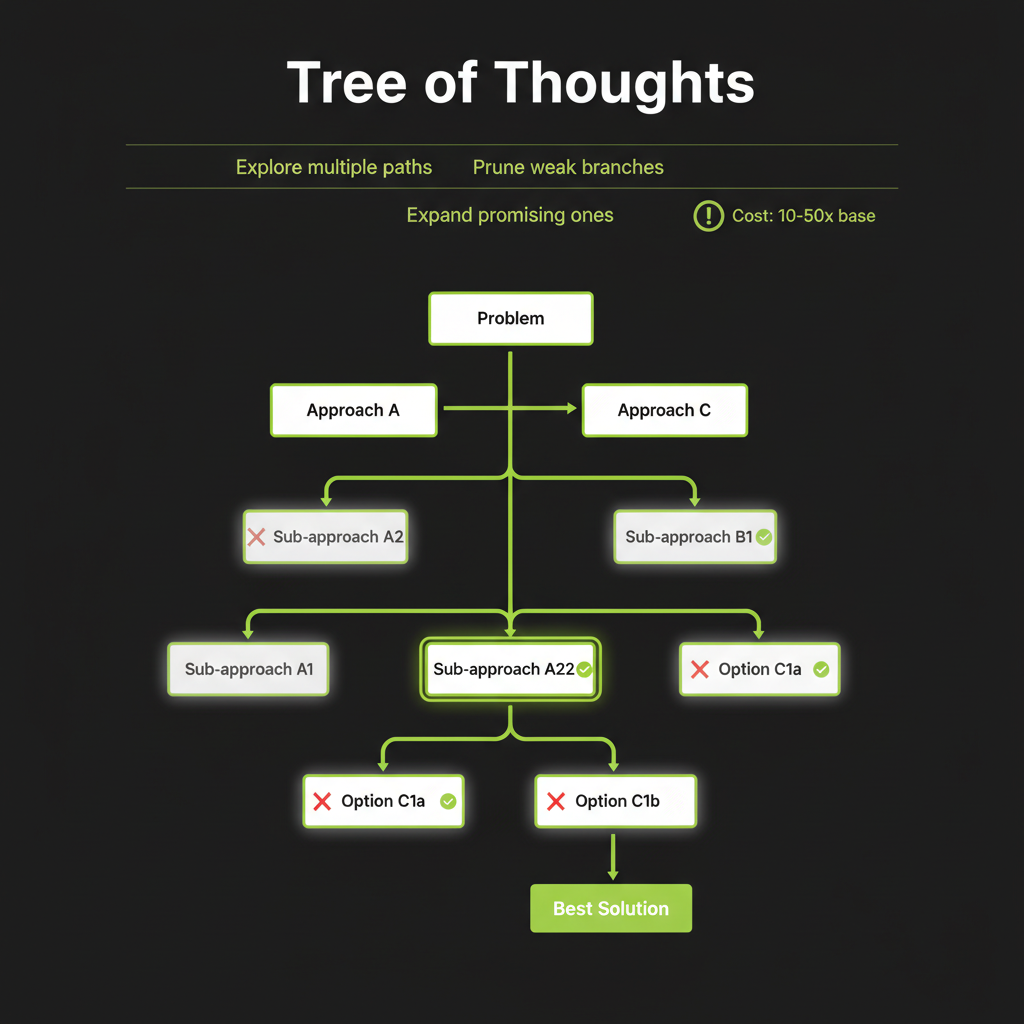
Explore, evaluate, prune, expand
The most structured approach. Instead of a single chain, explore multiple reasoning branches in parallel, evaluate which branches look promising, and expand only those:
[Problem]
/ | \
[Path A] [Path B] [Path C]
/ \ | \
[A1] [A2] [B1] [C1] <- evaluate, prune
| |
[A1a] [B1a] <- expand winners
|
[Answer]The algorithm works by: (1) Propose — generate multiple next-steps from the current state. (2) Evaluate — score each step using the model itself or a separate evaluator. (3) Search — use BFS or DFS to explore the most promising paths. (4) Backtrack — abandon dead ends and try alternatives.
Tree of Thoughts is expensive — 10–50x base cost. Exhaust cheaper techniques before reaching for it. Reserve it for genuinely hard problems where sequential reasoning repeatedly fails: complex planning, mathematical proofs, or puzzle-solving where the initial approach is often wrong.
Cost and quality profile
Cost: 10–50x base cost depending on branching factor and depth. Quality gain: Highest potential improvement, but only for problems that benefit from structured exploration. When to use: Very hard problems where cheaper techniques produce inconsistent or incorrect results.
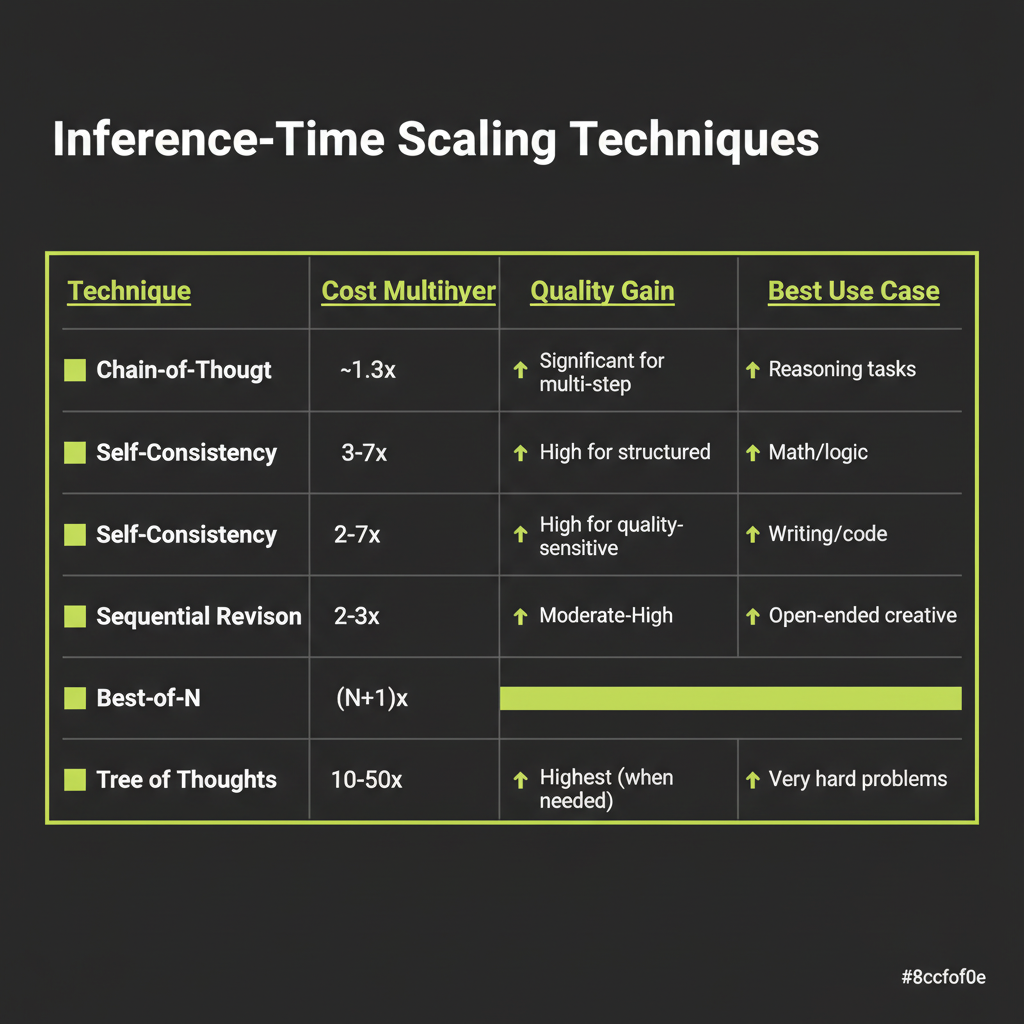
Technique Comparison and Selection
Here is the full comparison to guide your decision-making:
Technique | Cost | Latency | Best For
--------------------|-----------|-------------|---------------------------
Chain-of-Thought | ~1.3x | Same | Multi-step reasoning
Self-Consistency | 3-7x | Same (||) | Math, classification
Sequential Revision | 2-3x | 2-3x | Writing, code quality
Best-of-N | (N+1)x | Same (||) | Creative, subjective
Tree of Thoughts | 10-50x | 5-20x | Hard planning, proofsDecision heuristic
Start with Chain-of-Thought — it is almost free. If accuracy matters more than cost, add extended thinking (Module 10). If you need reliability on a specific task, benchmark self-consistency. For quality-sensitive generation, use sequential revision. For creative or subjective tasks, try best-of-N. Tree of Thoughts is a last resort for genuinely hard problems.
The Snell et al. paper revealed that compute-optimal allocation varies by difficulty. Easy questions benefit most from a single high-quality attempt. Hard questions benefit from multiple attempts or tree search. A system that dynamically allocates compute based on difficulty outperforms any fixed strategy.
Implement majority voting in TypeScript and compare it against single-shot accuracy on a multi-step problem.
- Choose a multi-step word problem — for example, "A store sells apples for $1.50 each. If you buy 7 apples and pay with a $20 bill, how much change do you get?"
- Run single-shot — call Claude once with the problem. Record the answer.
- Implement majority voting — use the
selfConsistencyfunction from this module with N=5 and temperature=0.7. - Compare results — did the majority vote match the single-shot answer? Try with a harder problem where single-shot fails. Does majority voting recover the correct answer?
- Measure cost — log token usage for both approaches. Calculate the cost multiplier.